Book Summary: หนังสือ Designing Machine Learning Systems ตอนที่ 2/2
Book Summary: หนังสือ Designing Machine Learning Systems ตอนที่ 2/2

…เพราะโปรเจกต์ AI เริ่มจากเดต้าไปหาลอจิก กลับทิศสลับทางกับวิธีการเขียนโค้ดแอปพลิเคชันแบบดั้งเดิม
ดังนั้น การบริหารโปรเจกต์ ML/AI จึงต้องคิดใหม่ บริหารใหม่ ทั้งในแง่กระบวนการเตรียมข้อมูล, วิธีเลือกใช้อัลกอริทึมและคัดเลือกโมเดล, การบริหารทรัพยากรและเงินทุน, ไปปไลน์, DevOps และการเตรียมทีมงาน สิ่งเหล่านี้จะอยู่ในเนื้อหา 11 บทของหนังสือ Designing Machine Learning Systems ของ Chip Huyen อาจารย์มหาวิทยาลัยสแตนฟอร์ด ผู้มีประสบการณ์บริหารโปรเจกต์ ML ให้กับบริษัทน้อยใหญ่กว่า 4 พันโปรเจกต์ ซึ่งหนึ่งในนั้น รวมถึงบริษัท Netflix และ NVIDIA บริษัทผู้ใส่ NPU หน่วยประมวลผลนิวรอลไว้ในชิปกราฟิกเป็นรายแรกของโลก
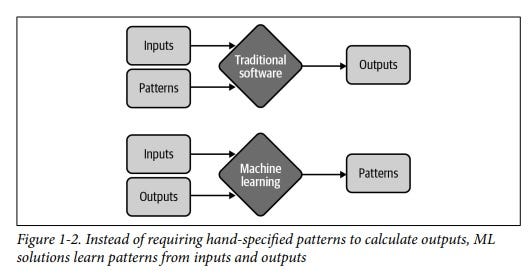
ก่อนจะสรุปย่อแต่ละบทของหนังสือเล่มนี้ ขอเท้าความกลับไปเมื่อ 3–4 ปีก่อน เมื่อคราวได้ดื่มด่ำเรียนเขียนโค้ดไปหลายชุดในคอร์สออนไลน์ของศาสตรจารย์แอนดรู อึ๊ง หนึ่งในผู้ก่อตั้งโปรเจกต์ Google Brain ตอนนั้น เกิดแรงบันดาลใจอยากจะทำโปรเจกต์ ML ส่วนตัว เกี่ยวกับเรื่องรู้จำเพื่อแยกแยะสินค้าแท้-ปลอมด้วยภาพถ่ายจากมือถือ (โมเดล Computer Vision) ในระหว่างที่รวบรวมข้อมูลและตระเวนปรึกษาหาความรู้จากอาจารย์มหาวิทยาลัยที่สนิทสนมรู้จัก ยิ่งคุยยิ่งเกิดคำถามมากมายในใจ แต่หาคำตอบชัดๆ ไม่ได้ เช่น
- หากสินค้าที่จะตรวจเช็คด้วย AI นั้น หายากราคาแพง ค่าจ้างทำป้ายกำกับก็แพง จำนวนภาพที่น้อยที่สุดที่วงการยอมรับได้เพื่อเทรนโมเดล คือเท่าไร ?
- หลักคิด วิธีเลือกใช้ “โค้ด-คน-เครื่อง” ?
- หลังเปิดให้ยูสเซอร์ใช้งาน ต้องใช้เงินลงทุนต่อเนื่องเท่าไร ? จะตอบหุ้นส่วนหรือนายทุนได้
- โมเดล ML ต้องอัพเดทมากน้อยแค่ไหน ? ถ้าอัพเดทบ่อย จะใช้คนทำงานประจำมากขึ้น ค่าใช้จ่ายก็จะมากขึ้น
หนังสือ Designing ML Systems เล่มนี้ เนื่องจากอาจารย์ Chip วางแผนไว้ใช้ประกอบการสอนวิชา CS 329S: Machine Learning Systems Design ของสแตนฟอร์ด จึงจัดระเบียบเนื้อหา “ตามวงจรชีวิตของโปรเจกต์ ML” โดยจุดเด่นที่สุดของเล่มนี้คือ “กรณีศึกษา — จากโลกธุรกิจจริง” ซึ่งไม่สามารถหาอ่านได้จากหนังสือเล่มอื่น และอาจารย์มหาวิทยาลัยจำนวนมาก (ณ ขณะที่เขียนบล็อก) ตอบผมไม่ได้
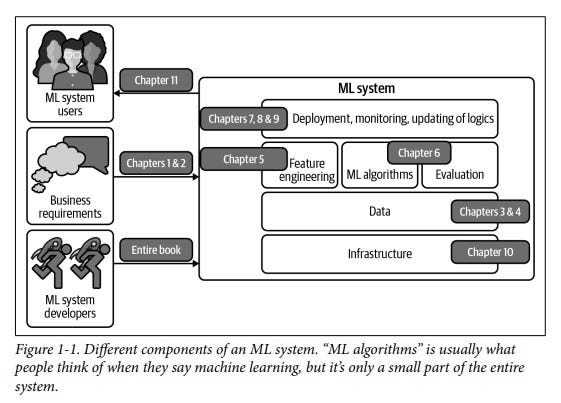
บทที่ 1 และ 2 ได้แพร่งพรายความลับทางการค้าผ่านกรณีศึกษาไว้จำนวนมาก คำถามที่ว่าต้องใช้กี่ตัวอย่างที่ตลาดยอมรับได้เพื่อเทรนโมเดล ผมได้คำตอบจากสองบทแรกนี้ รวมทั้งกรณีศึกษาจากบริษัทชื่อดังต่างๆ ที่กำลังแปลงโค้ดอิงลอจิกแบบดั้งเดิม ไปเป็น ML เพื่อแข่งขันและตอบโจทย์ยูสเซอร์ เนื้อหาเป็นการวางรากฐานหลักคิดและสร้างหลักบริหาร..คิดก่อนลงมือทำโปรเจกต์ โดยเริ่มจากคำถามพื้นฐานที่สุด “โปรเจกต์ของคุณจำเป็นต้องมี ML หรือไม่?” “การเลือกวัตถุประสงค์สำหรับโปรเจกต์ของคุณ” และ “วิธีตีกรอบโจทย์ให้แคบชัด เพื่อหาโซลูชั่นที่ง่ายกว่า”
ข้ามบทที่ 3 ไปก่อน ขออธิบายบทที่ 4 ถึง 6 ก่อน เนื้อหาชุดนี้เป็นระยะ pre-deployment หรือแนวคิดก่อนปรับใช้ของโปรเจกต์ ML โดยบทที่ 4 จะกล่าวถึงการเตรียมข้อมูลชุดฝึก เริ่มจากวิธีการสุ่มข้อมูลทั้ง 6 แบบ การทำป้ายกำกับด้วยมือและการแก้ปัญหากรณีป้ายกำกับไม่พอ การแก้ปัญหาคลาสหรือกลุ่มข้อมูลไม่สมดุล เช่น ข้อมูลภาพเอ็กซ์เรย์ปอดคนที่เป็นมะเร็งมีน้อยกว่าภาพปอดปกติอย่างมาก จะทำอย่างไรเพื่อไม่ให้โมเดลเบี่ยงเบน การสร้างข้อมูลเพิ่ม (data augmentation) ทั้ง 3 วิธี
สำหรับบทที่ 5 เป็นการสกัดหาฟีเจอร์จากข้อมูล การแก้ปัญหาข้อมูลหายไปบางฟิลด์บางช่อง ข้อมูลกรอกคนละฟอร์แมต การทำ Discretization หรือกระบวนการเปลี่ยนฟีเจอร์ชนิดต่อเนื่อง ให้เป็นชนิดไม่ต่อเนื่อง เป็นหมวดหมู่หรือเป็นช่วง การแก้ปัญหาข้อมูลรั่วปนเปื้อน (Data Leakage) มีข้อมูลแฝงจากสภาพแวดล้อมที่มีผลต่อการเบี่ยงเบนข้อมูลสำหรับเทรนโมเดล แล้วทำให้โมเดลทำงานผิดพลาด ฯลฯ สำหรับบทที่ 6 ซึ่งเป็นบทที่สนุกสำหรับผม เพราะเกี่ยวข้องกับอัลกอริทึม บทนี้จะเผย 6 เคล็ดลับในการเลือกอัลกอริทึมที่ดีที่สุดสำหรับงานของคุณ จากนั้นจะกล่าวถึงแง่มุมต่างๆ ของการพัฒนาโมเดล เช่น การดีบัก การติดตาม การทดสอบ การกำหนดเวอร์ชัน การฝึกโมเดลแบบกระจาย การใช้ “กลุ่มโมเดล” (Ensemble อ่านว่า ออนซอมเบิ้ล) เพื่อประสานเสียงทำงานร่วมกัน และ AutoML
ผมได้ตาสว่างเมื่ออาจารย์เฉลยว่า บริษัทขนาดใหญ่ไม่ได้ใช้ ML แค่โมเดลเดียวต่อหนึ่งแอพ (เหมือนที่ผมเคยคิดเมื่อหลายปีก่อน) แต่ประกอบร่วมหลายโมเดลและหลายชนิด ร่วมกันทำงานเป็นกลุ่มคณะ หรือออนซอมเบิ้ล ตัวอย่างเช่น Netflix หรือ Facebook ซึ่งทยอยเปลี่ยนโค้ดแบบดั้งเดิมไปเป็น ML ทีละกลุ่มงาน ดังนั้น อย่าแปลกใจหากการแสดงผลของ Netflix, Facebook หรือ Instagram บางครั้งมีอาการเอ๋อๆ ไปบ้างบางเวลา ก็เพราะการทดลองถอดเปลี่ยนโมเดลนี้เอง
การพัฒนาโมเดลเป็นกระบวนการแบบวนซ้ำ (iterative process) หลังจากการทำซ้ำแต่ละครั้ง คุณจะต้องเปรียบเทียบประสิทธิภาพของโมเดล กับประสิทธิภาพในการทำซ้ำครั้งก่อน แล้วประเมินว่าเหมาะใช้จริงเพียงใด ดังนั้น ตอนท้ายของบทที่ 6 นี้ จะมีเนื้อหาเกี่ยวกับวิธีประเมินโมเดล ครอบคลุมเทคนิคการประเมินต่างๆ รวมถึงการทดสอบการรบกวน, การทดสอบความไม่แปรปรวน (invariance tests), การคาลิเบรทโมเดล (model calibration), และการประเมินจากข้อมูลสไลซ์ (slice-based evaluation)

บทที่ 7 ถึง 9 ครอบคลุมขั้นตอนการปรับใช้และหลังการปรับใช้ของโปรเจกต์ ML โดยบทที่ 7 จะอธิบายการใช้ Batch Prediction กับ Online Prediction และการผสมผสานทั้งสองวิธีเข้าด้วยกัน, การลดขนาดโมเดลโดยเทคนิคต่างๆ รวมทั้งการใช้ Quantization ซึ่งผมเคยแลกเปลี่ยนความเห็นประเด็นนี้กับรุ่นน้องซึ่งเป็นหัวหน้าทีมงาน DirectML ที่เรดมอนด์, การปรับใช้ ML บนระบบคลาวด์และบนอุปกรณ์ขนาดเล็กอย่างเช่นโทรศัพท์มือถือ หรือกระทั่งบราวเซอร์ สำหรับบทที่ 8 เป็นเรื่องสาเหตุความล้มเหลวของระบบ ML ซึ่งโดยมากมักเกิดจากปัญหา Data Distribution Shifts ซึ่งยากต่อการ Monitor ระบบ ML ขึ้นกับเดต้าและบริบทที่เปลี่ยนแปลงตลอดเวลา ข้อมูลชุดฝึกเดิมอาจจะล้าสมัยไม่ทันกระแสสังคม เราจะรู้ทันและเฝ้าติดตามได้อย่างไร, ชนิดของการแจกแจงเปลี่ยน, เมตริกซ์ชี้วัดเพื่อการเฝ้าติดตาม และตัวอย่าง Toolbox เครื่องมือที่จะเข้ามาช่วยเพื่อลดงานน่าเบื่อจุกจิกเหมือนคอยป้องกัน Cyber Security Threats
ส่วนบทที่ 9 เป็นเรื่องใหญ่และใหม่สำหรับผม เป็นประเด็นที่ไม่เคยคิดไว้ก่อน นั่นคือ จะอัพเดทโมเดลในระหว่างเปิดให้บริการผู้ใช้อย่างไร จึงจะปลอดภัย ไม่เสี่ยงระบบล่ม และไม่กระทบ User Experience, จะออกแบบโครงสร้างพื้นฐานไอทีอย่างไร เพื่ออัพเดทโมเดลได้บ่อยเท่าที่ต้องการ, การออกแบบระบบเรียนรู้ต่อเนื่องอัตโนมัติเมื่อข้อมูลเปลี่ยน (Continual Learning), การทดสอบและคัดเลือกโมเดลแชมเปี้ยนเพื่อ “เข้ารอบแล้วไปต่อ”, วิธีการทดสอบโมเดลขณะที่กำลังเปิดใช้งานอยู่โดยไม่เสี่ยงไม่พัง มีเทคนิคหลากหลายที่เป็นตัวช่วยในเรื่องนี้ เช่น การปรับใช้แบบแชโดว์ (shadow deployment), การทดสอบ A/B, การวิเคราะห์แบบแคแนรี (canary analysis), การทดลองแทรกสอด (interleaving experiments) และแบนดิท (bandits)
ย้อนกลับไปบทที่ 3 แล้วผูกรวมกับบทที่ 10 เนื้อหาจะเน้นโครงสร้างพื้นฐานที่จำเป็น เพื่อให้ผู้มีส่วนได้ส่วนเสียจากภูมิหลังที่แตกต่างกัน เป้าหมายงานต่างกัน สามารถทำงานร่วมกันได้แล้วทำให้โปรเจกต์ ML ประสบความสำเร็จร่วมกัน บทที่ 3 เน้นเรื่องเดต้า ชนิดและรูปแบบฐานข้อมูลที่เหมาะสมสำหรับงาน ML หลักคิดเพื่อเลือกระหว่าง data warehouse และ data lake เป็นต้น สำหรับบทที่ 10 เน้นที่โครงสร้างพื้นฐานการประมวลผลและแพลตฟอร์ม ML รวมทั้งเครื่องมือสำหรับเป็น MLOps การสร้างที่เก็บแบบ Model Store และ Feature Store คืออะไร ฯลฯ
สำหรับบทสุดท้าย บทที่ 11 เกี่ยวกับเรื่องคนและการบริหาร เป็นบทที่โปรแกรมเมอร์และนักวิจัย ML ไม่ชอบอ่าน(และไม่อยากรับรู้) โดยเฉพาะเรื่องข้อมูลความเป็นส่วนตัว ซึ่งบริษัทและ CIO/MIS Manager ต้องปฏิบัติตามกฎหมาย (PDPA, GDPR, ฯลฯ) โดยยกเคสหรือกรณีศึกษาที่เกิดขึ้น และพูดถึงเฟรมเวิร์คสำหรับ AI ที่มีความรับผิดชอบคืออะไร? และอาจจะกลายเป็นมาตรฐานอุตสาหกรรมเหมือน ISO ในอนาคต
หนังสือเล่มนี้อาจจะไม่สามารถไขปัญหาเปิดทางสว่างได้ในทุกคำตอบ โดยเฉพาะคำตอบที่ต้องลงมือปฏิบัติเองจึงจะรู้แจ้งเห็นปัญหาจริง หนังสือเล่มนี้ เป็นเล่มที่ผมไม่เคยเห็นไม่เคยได้อ่านจากตำรา AI ทั่วไป จึงหยิบยกมาทำ Book Summary สำหรับผู้อ่าน โดยหวังว่าคงมีประโยชน์ไม่มากก็น้อย และขอขอบคุณที่ติดตามอ่าน
*********
ติดตามบทความ AI.Neuro.Pal ได้ที่
Facebook: www.facebook.com/ai.neuro.pal
Twitter: https://twitter.com/AiNuero
Blogger: https://aineuro9.blogspot.com
Medium: https://medium.com/@AiNeuroPal



ความคิดเห็น
แสดงความคิดเห็น